


Watermarks have been used for centuries on paper materials like currency, postage stamps, official documents, and high-quality stationery or stock certificates. They help prove validity and prevent unauthorized copying. Watermarks are designed to be faint or transparent enough to allow the main content (such as an image) to be seen clearly but still be detectable and identifiable upon close inspection. In the realm of images or video, digital watermarks can embed copyright, licensing, or tracking data without noticeably altering quality, thus helping to assert rights ownership. Companies, authors, and artists use non-removable watermarks to sign their original creative works with their brand or identity, making unauthorized copies harder to claim as one's own creation. Removable watermarks are applied to review copies of content meant for evaluation but not full use, which are removed upon license payment.
Why I am talking about watermark?
As the world of generative AI expands, creators face bigger problems, and intellectual property issues remain unresolved. AI tools like Stable Diffusion, Midjourney, and DALL·E 2 are capable of creating stunning images, ranging from the look of vintage photos and watercolor paintings to sketches and Pointillism. With advancements in technologies like Sora and Runway, video generation has become easier than one might imagine. But how can we detect whether something is AI-generated or human-made?
How do we think about watermarking for AI generated content?
Image models:
For AI-generated images there are few techniques to watermark images:
1. Metadata watermarking - Most image formats like JPEG or PNG allow embedding custom metadata like copyright, author, and licensing info. This metadata persists as the image is shared and can show the origin if an AI generated it.
2. Visible overlays - Adding a faint translucent logo or signature overlay onto the corner of the image works as a visible watermark. This is easy to implement but can obscure parts of the image. We have seen this often with "Getty" images.
3. Pixel pattern watermarking - Slight intentional perturbations can be added to specific pixels of the image based on a secret key. These minor changes are indiscernible but the pattern can be detected to verify the author.
4. Noise injection - Unique high-frequency noise signals with specified properties can be algorithmically added to the pixel data. This noise is invisible but can be extracted with the right tools to authenticate authorship.
5. Model fingerprints - The model itself naturally leaves subtle hints of structural artifacts that can signal its identity. With analysis, images can be definitively matched to their originating model.
The core idea behind AI image watermarking is to embed some form of signature without affecting visual quality. Many recent AI image generation models, including Amazon Titan's image generator which is in preview, enables users to create image but also detect if there are any watermark in the image.
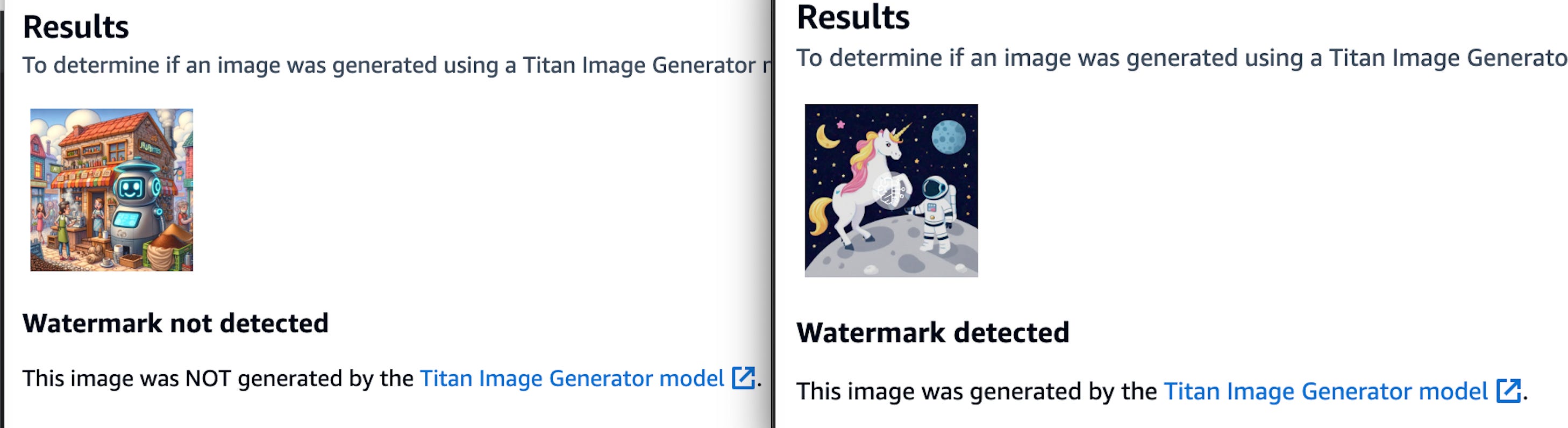
In the side-by-side image above, the left image was created by DALL·E, while the right image was generated by Amazon Titan Image Generator. As we can see, the watermark detection technique applied by Amazon Titan was able to detect the image created by their own model but not by the DALL·E model.
While it's not possible to identify which model, outside of Amazon Titan, created the image, this is still a good start for identifying images generated by AI tools. Much research is happening in this area, and more developments are expected as we advance the science.
Text generators:
While it may be relatively easy to create a watermark in image generated by AI, how do we solve it for text generated by AI?
It's a research area but here are some methods that can be used to watermark AI-generated text:
1. Synonym substitution - Subtle word substitutions using synonyms can encode information into the text. Specific words picked through a key get swapped for synonym alternatives to convey a pattern while preserving meaning.
2. White text embedding - Invisible white colored texts containing signatures can be embedded in between lines. These can only be spotted in text editors and act as indicators of origin.
3. Semantic hashing - Hashing signatures derived from the content itself can be appended/prepended to the text dynamically maintaining coherence in the language.
4. Intentional misspellings - Similar sounding typos and misspellings can also encode watermark patterns. As long as readability is intact, slight misspellings and errors precisely introduced across words and sentences can contribute to a robust signature.
5. Syntax-based - Syntax features like specific punctuation, grammar constructs, line breaks etc. not impacting readability can be molded into a style reflecting markers of authorship. The structural style encodes the identity.
The core idea in AI text watermarking is to hide signatures in discreet features tolerant to revisions while maintaining readability. It requires a balanced choice of linguistic traits leveraged judiciously through an intentional key-based mapping.
A recent publication from AI research team at META suggests that watermarking language models (LLMs) makes them "radioactive" 😮, due to the capacity of watermarked text to contaminate a model when used as fine-tuning data.
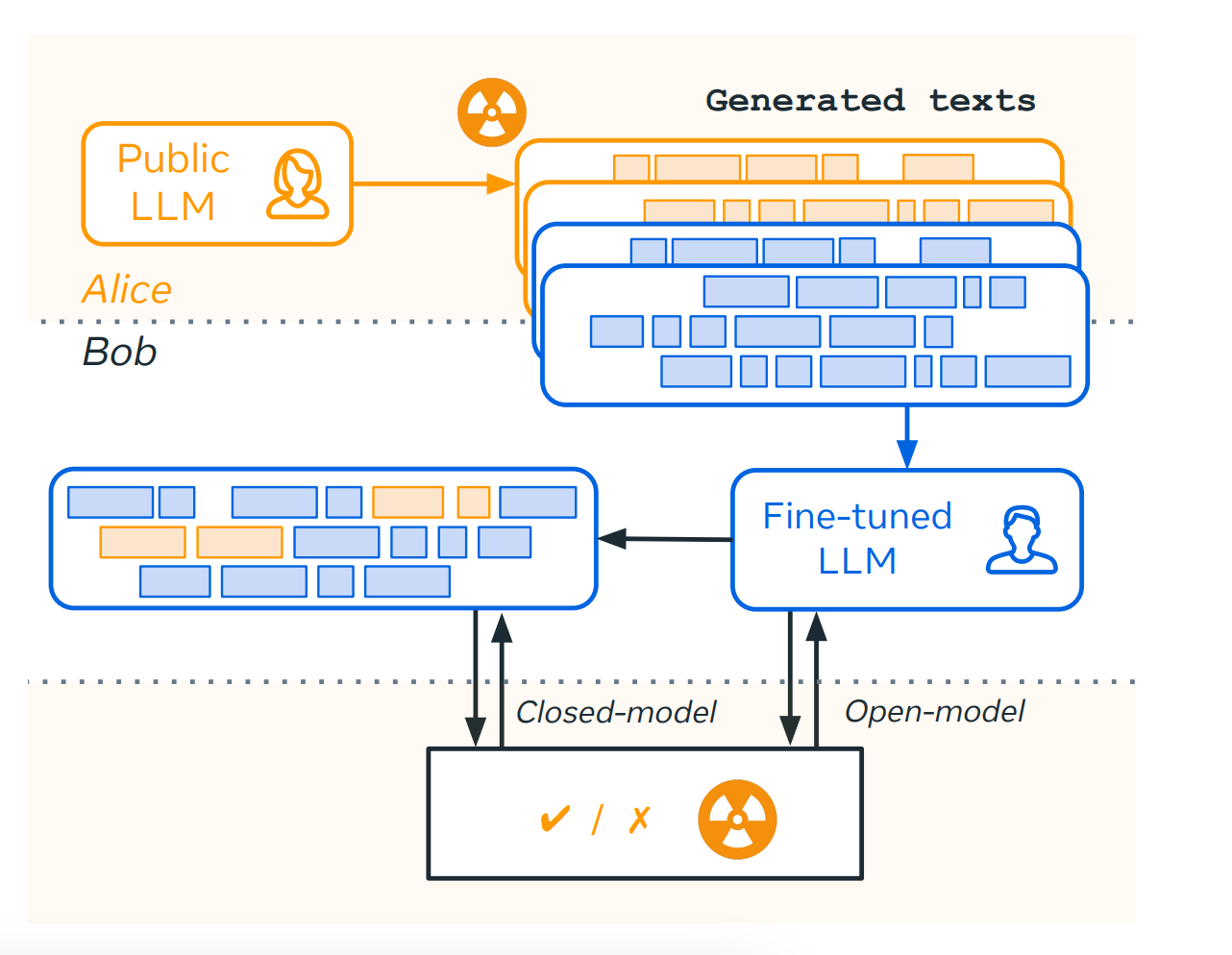
Let's dive a little deeper. As we have heard a few times now that by 2024, we will run out of high-quality data to train LLMs. What does this mean for companies that want to continually build LLMs but can't find the data? Well, they create synthetic datasets. How do you do that? Well, find a public LLM (e.g., GPT-4 😉) and create synthetic datasets. Use that to train your own model. What's the issue here?
Some LLM providers have been accused of using outputs from GPT-4 to train and fine-tune their own commercial models, possibly not aligning with OpenAI's terms of use. If OpenAI is watermarking their text data with their own techniques, the synthetic data produced via GPT-4 or any other public LLMs may become watermarked themselves. This could provide a legal mechanism for OpenAI to pursue legal action against their competitors, assuming the New York Times (or now even Elon Musk) doesn't take them out first 🤣.
There are other study on the robustness of watermarked text after it is rewritten by humans, paraphrased by a non-watermarked LLM, or mixed into a longer hand-written document, have found that watermarks remain detectable even after human and machine paraphrasing.
Although technologies such as watermarking are not flawless, for real-world deployment, it's crucial that detection methods ensure minimal false-positive rates. This necessity must be balanced with the need for detection sensitivity, considering the significant harm that each false positive could cause.
What do you think?
Shameless plug:
Do you like what I write on this topic? In my "AI for Leaders" course, I cover topic exactly like this, on what leaders have to focus when adopting AI in an enterprise. Along with the cost, course also cover pertinent topics like:
How to assess current state of AI
AI strategy framework
Risk and Regulation
Defining AI vision for your company
Organization and talent strategy
Implementation guidelines
and much more..
My February cohort is scheduled to begin on 16th March, 2024. Please sign up and immerse yourself in the world of AI. Whether you're an executive, a manager, or an aspiring leader, this course will empower you to be at the cutting edge of AI leadership.
Don't just watch the AI transformation unfold – be a part of it!
