
Breaking New Ground: The Evolution of AI Hardware Technology


In this article, we're taking a close look at the latest leaps in AI hardware, where big names and new players are pushing the limits of what's possible. We're talking about the huge steps forward with NVIDIA's new Blackwell series and how Cerebras' CS-3 system is setting new benchmarks. These advancements aren't just about faster computers; they're changing the game in terms of what AI can do, from smarter apps to more complex problem-solving. As AI continues to evolve, the hardware behind it is keeping pace, promising an exciting future where technology transforms our world in even more amazing ways.
The world of AI is moving at the pace unseen and unheard of and to support this (age old) newly minted industry, there is a race in AI hardware to capture the market.
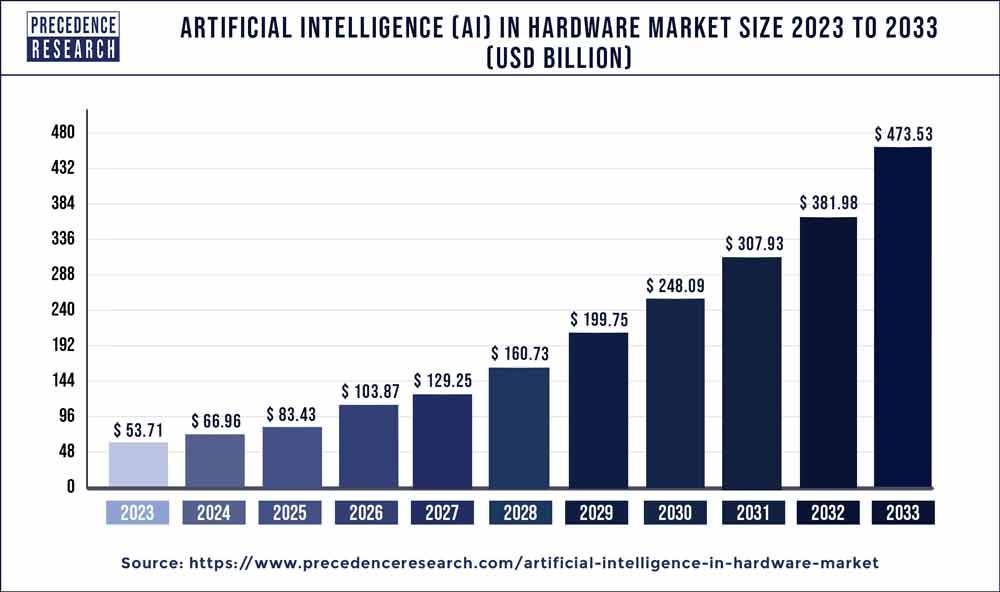
As per Precedence Research, the global AI in hardware market size was valued at USD 53.71 billion and it's projected to surpass around USD 475.33 billion by 2023 - growing at compound annual growth rate (CAGR) at 24.3% from 2024 to 2033.
Who are the providers:
If you are following stock market, you know that NVIDIA is killing on the wall street with last 12-months growth of USD 641 or 245% in their stock price.
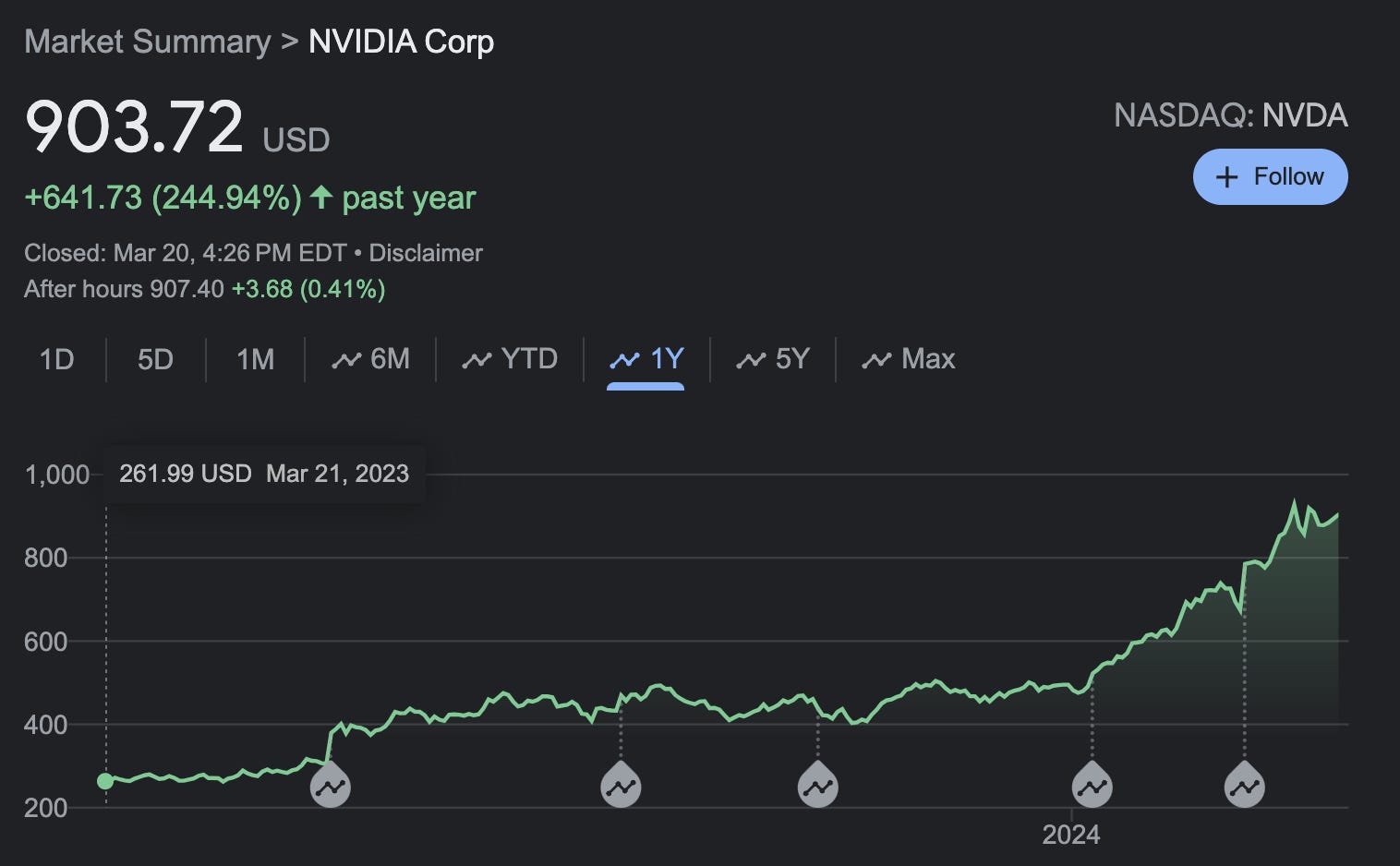
While there is NVDIA and there is rest of them - AMD (87% stock price growth last 12 months), Intel (48% stock price growth last 12 months), Qualcomm (35% stock price growth last 12 months). Though stock price can not be considered as success of the company, that's the reality of this world.
AI is advancing in the large language and vision space (GPT-4, Claude3, Mixtral, Grok-1, LLaMa 2, etc.) and there is a trend that startups like OpenAI, Anthropic and Mistral are developing State-of-the-art (SOTA) models which mesmerizes us. Similar trend has been happening in the hardware space as well.
There is NVIDIA, AMD, and Qualcomm who are mainstream provider and there are startups who are innovating in this space such as Cerebras, Groq. The most popular hardware from NVIDIA are A100 and H100, from AMD it's MI250 and MI300, while Qualcomm has Cloud AI 100.
This week in their annual conference, NVIDIA announced their newest hardware called Blackwell series B100/B200 which is bigger than their earlier generation of A100/H100.

What is Blackwell series B100/B200:
It's named after Dr. David Harold Blackwell, an American statistics and mathematics pioneer, who, among other things, wrote the first Bayesian statistics textbook. Blackwell-architecture GPUs pack 208 billion transistors. It feature two reticle-limited dies connected by a 10 terabytes per second (TB/s) chip-to-chip interconnect in a unified single GPU. That's a lot of transistors in a single chip. How does this compare against it's previous generation? Thankfully AnandTech has done that comparison.
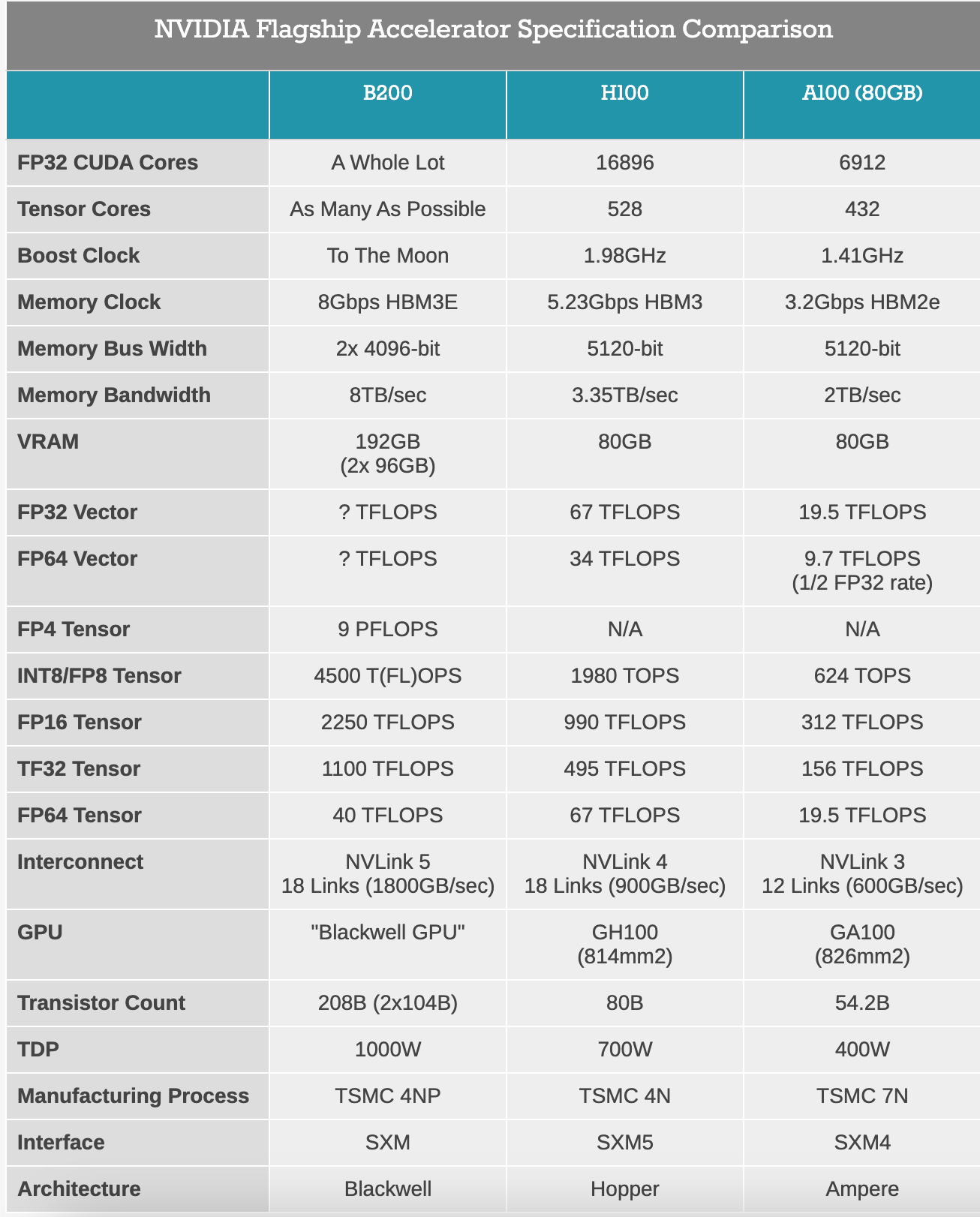
Now, there are lot of numbers in above table but let's understand some jargons like TFLOPs, VRAM. This newsletter audience is used to simple understanding of complex terms, so let me break it down for you.
TFLOPs:
TFLOPS is a measure of how many trillion (tera) floating-point operations (FLOPS) your GPU can perform in one second. Let’s consider an analogy of book reading and let’s estimate how many books a GPU with 1000 TFLOPS could theoretically "read" in a second.
Assumptions:
An average book contains 100,000 words.
Each word can be represented by a 32-bit floating-point number (4 bytes).
The GPU can perform one floating-point operation per word.
Let’s calculate the number of words a 1000 TFLOPS GPU can process in a second. 1000 TFLOPS = 1000 × 10^12 FLOPS (floating-point operations per second) = 1,000,000,000,000,000 FLOPS = 1 quadrillion FLOPS
Let’s convert the number of words to the number of books. Number of books = Number of words ÷ Words per book = 1 quadrillion ÷ 100,000 = 10,000,000,000 books.
Therefore, a GPU with 1000 TFLOPS could theoretically "read" or process the equivalent of 10 billion books in a single second, assuming each book contains 100,000 words. For example, New York public library system has over 55 million books/e-books and all of these can be read by GPU with 1000 TFLOPs in just few seconds (remember not all books are 100,000 words 😊)
This is a simplified analogy, and in reality, GPU workloads involve more complex operations than just counting words!
Keep in mind that TFLOPS is just one aspect of GPU performance, and other factors like memory and architecture also play a role in how well a GPU performs in real-world applications.
VRAM and SRAM:
So going with New York public library example, imaging a librarian working at the library's reference desk. They keep a small collection of the most frequently requested books right behind the desk for quick access. When someone asks for one of these popular books, the librarian can quickly grab it and hand it over without having to search through the entire library. This small collection of readily accessible books is like SRAM (Static Random Access Memory). SRAM is typically tied to the CPU as L1/L2 cache for quick access.
Now, imagine a special section of the library dedicated to comic books, graphic novels, and art books. This section has its own librarian who specializes in these visual materials and can quickly find and retrieve any book in this collection. The comic book section is separate from the main library and has its own organization system tailored for visual content. This specialized section is like VRAM (Video Random Access Memory). VRAM (Video Random Access Memory) is a special type of memory that is specifically designed to work with the graphics card (GPU).
Memory bandwidth:
Sticking to our library example, let’s imagine a library with multiple librarians who help their members to find and check out books. In this analogy, the librarians represent the memory controller, and the members represent the GPU or CPU requesting data from memory. Memory bandwidth is like the total number of books the librarians can collectively retrieve and hand over to the members in a given time period, say one minute. The higher the memory bandwidth, the more books the librarians can process per minute.
Let's dive deep
With some of the basic concepts out of the way, let's explore why everyone is talking about this new chip?
With 72 petaFLOPs on NVIDIA’s B200 GPU, it can perform 72,000 TFLOP per second. That's a LOT of operations per second. Going back to book analogy, that’s processing 720 billion books per second.
On the memory side, NVIDIA’s B200GPU has 96GBx2 == 192GB memory. That’s VRAM not an SRAM. So from our example of library, that memory is available in separate section.
On the memory bandwidth side, NVIDIA’s B200 has 8TB/sec.
Overall, I think this is a massive upgrade compared to their previous generations of H100 and A100 GPUs. I am sure that NVIDIA will be able to sell them very easily just because of the amount of compute power customers get. Since we don’t know the price of the GPU, we can’t comment on price/performance in comparison to H100 and A100.
Is this it?
Are there no other hardware providers that come close to this specification?
Well, hold your horses!
🥁 Enter Cerebras Systems !!
While this article is by no means a comparison of NVIDIA and Cerebras, it wouldn’t be fair not to mention that there is at least one company that has higher specifications, including a bigger chip than B200.
Cerebras’ CS-3 system was launched the same week as NVIDIA’s B200 series.
Core count: CS-3 has 4 trillion transistors compared to 208 billion transistors in B200. Almost 20x more.
TFLOPs: CS-3 can perform 125 petaFLOPs in comparison to 72 petaFLOPs on B200. Almost 75% more. So reading almost twice the number of books from our analogy.
RAM: While B200 and all the NVIDIA’s GPUs operate at VRAM level, CS-3 operates at SRAM level. If you recall, SRAM is faster as it's used for quick access. With a memory bandwidth of 21 petabytes per second in CS-3, the 8 terabytes per second memory bandwidth on B200 seems significantly lower (2600x lower). That means those librarians can access 2600 books with CS-3 but only 1 book with B200.
Size: In terms of dimensions, the CS-3 chip is significantly larger than B200. Don’t believe me? Here is a picture 😎

Just to reiterate, this article is not about comparing NVIDIA to Cerebras. NVIDIA is a very established company (~ USD 2 trillion market cap) and has very powerful software stack on top of their chipsets, such as CUDA and many more. Almost every scientist I know has used CUDA to build something novel. On the other hand, Cerebras is a startup with its 3rd generation of hardware being launched this week.
Summary
In summary, the AI hardware landscape is evolving at an extraordinary pace, driven by both technological advancements and the increasing complexity of AI models and applications. As we continue to push the boundaries of what's possible with AI, the hardware that powers these innovations becomes ever more critical.
It’s really an exciting time to be alive as we are making generational shift and impacting how mankind will operate their lives in coming years.
(disclaimer: at the time of writing this article, author works for Cerebras Systems)
Shameless plug:
Do you know someone who can benefit by learning the fundamentals of Artificial Intelligence (AI) and Machine Learning (ML)? You are in luck!
I have created a fundamental course on AI/ML where I explain this complex topic is the most simply way - some of my students calls it "oversimplifying"!
Click on this link and gift them the course - and yes, they do not need technical background. I mean it - else they get their money back! Guarantee!
